Excel Format (Advanced)
Structure used in the example
The following is the bean type definition to be used in the example.
<bean name="Type1">
<var name="a" type="int"/>
<var name="b" type="string"/>
<var name="c" type="bool"/>
</bean>
<bean name="Type2">
<var name="a" type="int"/>
<var name="b" type="bool"/>
<var name="c" type="Type1"/>
</bean>
<bean name="Vec3" sep=",">
<var name="x" type="float"/>
<var name="y" type="float"/>
<var name="z" type="float"/>
</bean>
<bean name="Type3">
<var name="a" type="int"/>
<var name="b" type="bool"/>
<var name="c" type="Type1#sep=,"/>
</bean>
<bean name="Type4">
<var name="a" type="string"/>
<var name="c" type="Vec3"/>
</bean>
<bean name="Title0">
<var name="a" type="int"/>
<var name="b" type="bool"/>
<var name="c" type="Title1"/>
</bean>
<bean name="Title1">
<var name="a" type="int"/>
<var name="b" type="string"/>
<var name="c" type="Title2"/>
</bean>
<bean name="Title2">
<var name="a" type="int"/>
<var name="b" type="int"/>
</bean>
Constant alias
When planning to fill in data, sometimes you want to use a string to represent an integer for easy reading and less error-prone.
Define the constalias constant alias in the xml schema file and use it when filling in data.
Note! Constant aliases can only be used for data of the byte, short, int, long, float, double type, and are only effective in the excel family (xls, xlsx, csv, etc.) and lite type source data types.
Constant aliases have no concept of namespace and are not affected by module names.
<mdoule name="test">
<constalias name="ITEM0" value="1001"/>
<constalias name="ITEM1" value="1002"/>
<constalias name="FLOAT1" value="1.5"/>
<constalias name="FLOAT2" value="2.5"/>
</module>

Limit column format
Using the title row and multi-level title row, you can accurately limit a certain data to a certain column range.
For simple type data with only one atomic value, in the qualified column format, since it is very clear that its value must come from a certain cell, it supports default value semantics, that is, if the cell is empty, the value takes the default value, for example, the default value of int type is 0, and the default value of int? is null.
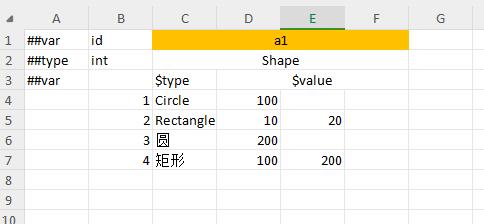
In the qualified column format, polymorphic bean types need to use the $type column to specify the specific type name, and nullable bean types also need to use the $type column to indicate whether it is a valid bean or an empty bean.
If the lowest level qualified column type is container or bean, since the qualified column only limits the overall range of the data, but does not limit the range of sub-data, the format for reading sub-data is streaming format, that is, each sub-data is read in sequence.

flags=1 enum type supports column qualification mode.
Use enumeration items as column names, and the final value is or value of all non-0 or empty enumeration items.
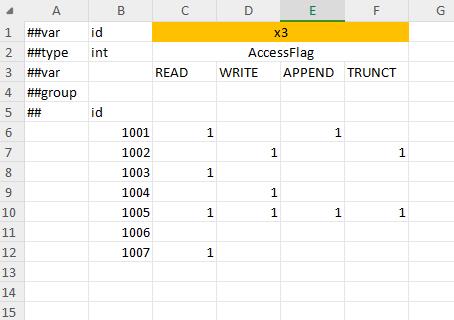
Polymorphic beans support a mixed filling method of $type and $value configured separately, column restriction or stream format
That is, use the $type column as the restriction type, use the $value column to restrict the actual field of the bean, and fill all the fields of the bean in $value in a stream format.
Map column restriction format
There are two filling methods:
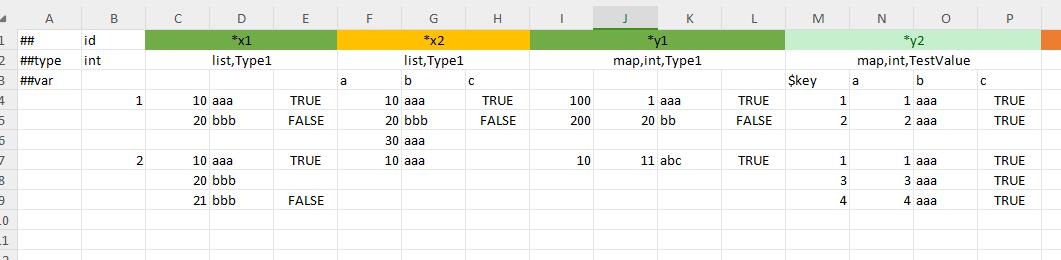
Multi-line filling method. In this case, the
$keysub-column is required to correspond to the key field, and the remaining columns correspond to the sub-fields of the value. As shown in the y1 field in the figure belowNon-multi-line filling method. The key can be used as the sub-field name. If the corresponding cell is not empty, the corresponding key-value pair exists. For example, in the following figure, the record with id=1, its y2 field has a final value of
{{"aaa", 1}, {"ccc":2}}; the record with id=2 has a final value of{{"bbb", 10}, {"ccc", 20}, {"ddd", 30}}. As shown in the y2 field in the following figure
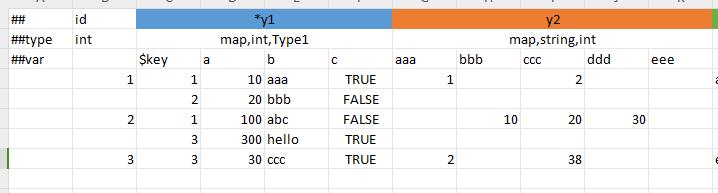
The above is only the filling method under the column-limited format of map. There are two additional filling methods under the flow format of map.
Multi-level title header
Sometimes, some fields are composite structures, such as beans or structure lists. When filling in order, blank cells will be automatically skipped in the flow format, which makes it easy to write errors in practice. In addition, the flow format does not support blank cells to represent default values, and it is also impossible to intuitively limit a subfield to a certain store, which brings some inconvenience. Multi-level titles can be used to limit the sub-fields of beans or containers, which improves readability and avoids unexpected errors in streaming formats.
By adding a new line ##var under a ##var line, you can set a title for the sub-field to add a sub-field name. There can be any level of sub-title headers.
In the figure below, x1 has only 1 level of sub-title headers, y1 has 2 levels, y2 has only 1 level, and z1 has 3 levels.

Multi-line structure list
Sometimes each structure field of the list structure is too many. If it is expanded horizontally, it will occupy too many columns and is not convenient for editing. If the table is split, it will be inconvenient for both programming and planning. In this case, you can use multi-line mode.
Marking the field name as *<name> can express that you want to read this data in multiple lines. Supports multi-line structure lists of any level (that is, each element in the multi-line structure can also be multiple lines).
For structural container types such as array,bean and list,bean, you can also use the limited column format to limit the columns of each subfield in the element, as shown in field x2.
Compact format
If a data is non-atomic data (such as bean or container), and it is limited to a certain cell column range or part of the data separated by sep, its parsing method is compact format.
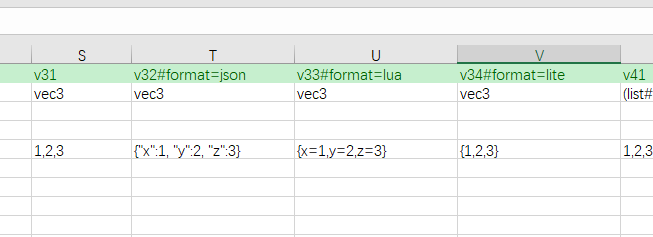
Because the compact format is relatively complex, it is introduced in a separate document. For details, see Excel compact format.
Data tag filtering
During the development period, some configurations that are only used for development are often made, such as test props, such as configurations used for automated testing. Developers hope not to export these data when they are officially released.
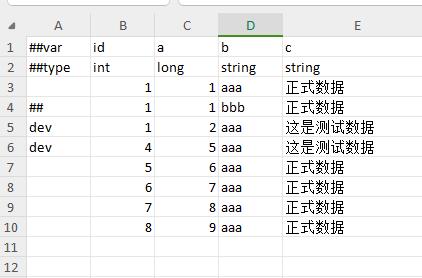
This can be achieved by adding tags to the records and then using the command line parameter --excludeTag. ## is a special tag, which means that this data is permanently annotated and will not be exported under any circumstances.
For detailed documentation, please read data tag.
As shown in the figure below, after adding the --excludeTag dev parameter in the command line, the two dev records of id=3 and id=4 will not be included in the export.