excel格式(高级)
示例中用到的结构
以下是示例中要用于的bean类型定义。
<bean name="Type1">
<var name="a" type="int"/>
<var name="b" type="string"/>
<var name="c" type="bool"/>
</bean>
<bean name="Type2">
<var name="a" type="int"/>
<var name="b" type="bool"/>
<var name="c" type="Type1"/>
</bean>
<bean name="Vec3" sep=",">
<var name="x" type="float"/>
<var name="y" type="float"/>
<var name="z" type="float"/>
</bean>
<bean name="Type3">
<var name="a" type="int"/>
<var name="b" type="bool"/>
<var name="c" type="Type1#sep=,"/>
</bean>
<bean name="Type4">
<var name="a" type="string"/>
<var name="c" type="Vec3"/>
</bean>
<bean name="Title0">
<var name="a" type="int"/>
<var name="b" type="bool"/>
<var name="c" type="Title1"/>
</bean>
<bean name="Title1">
<var name="a" type="int"/>
<var name="b" type="string"/>
<var name="c" type="Title2"/>
</bean>
<bean name="Title2">
<var name="a" type="int"/>
<var name="b" type="int"/>
</bean>
常量别名
策划填写数据的时候,有时候希望用一个字符串来代表某个整数以方便阅读,同时也不容易出错。
在xml schema文件中定义constalias常量别名,在填写数据时使用它。
注意!常量别名仅能用于byte、short、int、long、float、double类型的数据,并且仅在excel族(xls、xlsx、csv等)、lite类型源数据类型中生效。
常量别名没有命名空间的概念,不受module名影响。
<mdoule name="test">
<constalias name="ITEM0" value="1001"/>
<constalias name="ITEM1" value="1002"/>
<constalias name="FLOAT1" value="1.5"/>
<constalias name="FLOAT2" value="2.5"/>
</module>

限定列格式
通过标题行及多级标题行,可以精确限定某个数据在某些列范围内。
对于只有一个原子值的简单类型数据,限定列格式下,由于能够非常清晰知道它的值必然来自某一单元格,所以它支持默认值语义,即如果单元格为空,值取默认值,例如 int类型默认值为0,int?默认值为null。
限定列格式下,多态bean类型需要用 $type 列来指定具体类型名,可空bean类型也需要用$type列来指示是有效bean还是空bean。
如果最低层的限定列的类型为容器或者bean,由于限定列只限定了该数据整体范围,但未限定子数据的范围,因此读取子数据的格式为流式格式,即按顺序读入每个子数据。

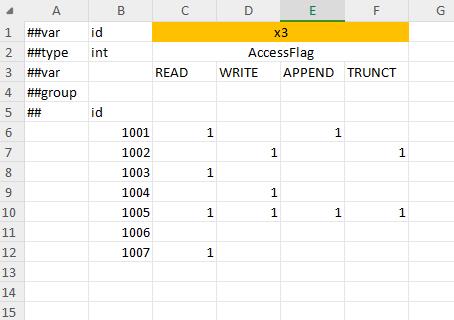
flags=1 的 enum 类型支持列限定模式。
用枚举项作为列名,最终值为所有非0或空的枚举项的或值。
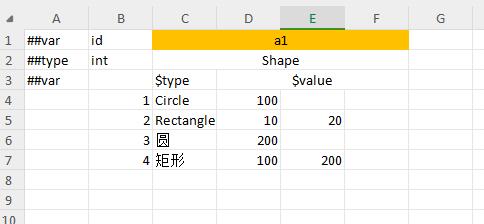
多态bean支持 $type与$value 分别配置的列限定或流式格式的混合填写方式
即用$type列为限定类型,用$value列来限定bean的实际字段,并且$value中以流式填写bean的所有字段。
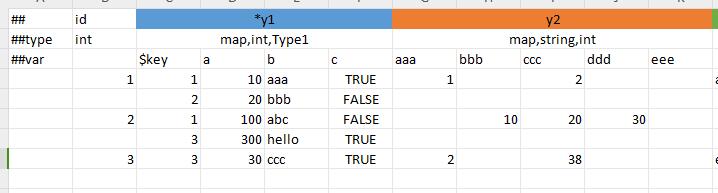
map的列限定格式
有两种填法:
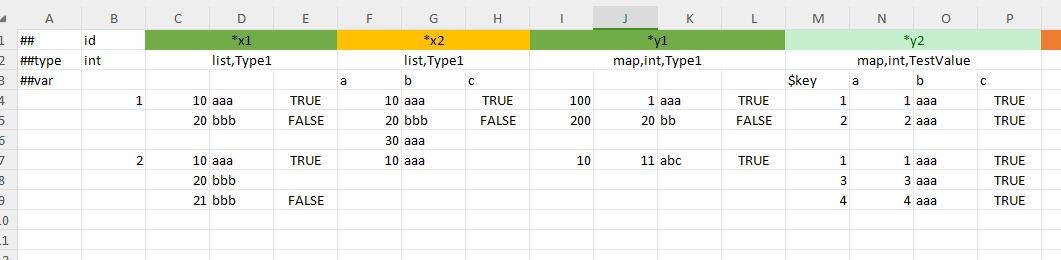
- 多行填法。此时要求
$key子列对应key字段,剩余列对应value的子字段。如下图y1字段所示 - 非多行填法。可以将key作为子字段名,如果对应的单元不为空,则对应key-value的键值对存在。例如下图中id=1的记录,
它的y2字段最终值为
{{"aaa", 1}, {"ccc":2}};id=2的记录,它的y2字段最终值为{{"bbb", 10}, {"ccc", 20}, {"ddd", 30}}。 如下图y2字段所示
以上仅是map的列限定格式下的填法。map还有额外两种流式格式下的填法。
多级标题头
有时候,某些字段是复合结构,如bean或者结构列表之类的类型,按顺序填写时,由于流式格式中空白单元格会被自动跳过, 导致实践中容易写错。另外,流式格式不支持空白单元格表示默认值,也无法直观地限定某个子字段在某一铺,带来一些不便。 多级标题可以用于限定bean或容器的子字段,提高了可读性,避免流式格式的意外错误。
通过在某个##var行下新增一行##var,为添加子字段名,则可以为子字段设置标题头。可以有任意级别的子标题头。
下图中,x1只有1级子标题头,y1有2级,y2只有1级,z1有3级。

多行结构列表
有时候列表结构的每个结构字段较多,如果水平展开则占据太多列,不方便编辑,如果拆表,无论程序还是策划都不方便,此时可以使用多行模式。
将字段名标记为*<name>即可表达要将这个数据多行读入。支持任意层次的多行结构列表(也即多行结构中的每个元素也可以是多行)。
对于array,bean、list,bean这样的结构容器类型,还可以配合限定列格式,限定元素中每个子字段的列,如字段x2所示。
紧凑格式
如果某个数据是非原子数据(如bean或容器),并且它被限定到某些单元格列范围或者是sep分割的数据的一部分,则它的解析方式为紧凑格式。
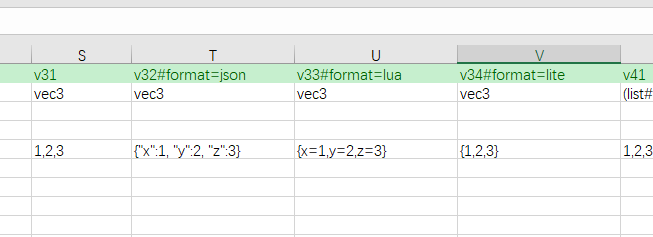
由于紧凑格式比较复杂,单独用一篇文档介绍它。详细见Excel紧凑格式。
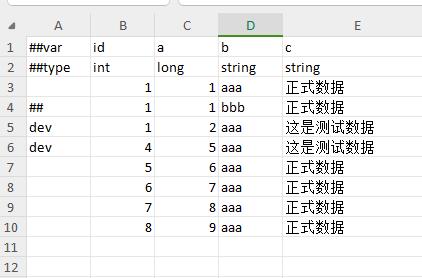
数据标签过滤
开发期经常会制作一些仅供开发使用的配置,比如测试道具,比如自动化测试使用的配置,开发者希望在正式发布时不导出这些数据。
可以通过给记录加上tag,再配合命令行参数 --excludeTag实现这个目的 。##是一个特殊的tag,表示这个数据被永久注释,任何情况下都不会被导出。
详细文档请阅读 数据 tag。
如下图,id=3和id=4的记录,在命令行添加 --excludeTag dev 参数后,导出时不会包含这两个dev记录。