Excel compact format
Introduction
If a data is non-atomic data (such as beans or containers), and it is limited to certain cell column ranges or is part of the data separated by sep, it is parsed in compact format.
Before luban v4.0.0, only the stream format is supported as a compact format. Since v4.0.0, the following compact formats are supported:
- Stream format
- lite concise format
- json format
- lua format
Specify the compact format used for excel data
Note that the format attribute is defined on the field name, not on the type!
Configure the format attribute on the field header to specify the format for parsing compact data, such as position#format=lite. If no format is specified for the field, the default compact format is stream.
The compact format has the following types:
stream
lite
json
lua
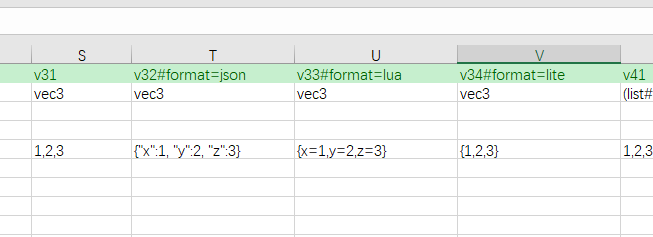
The stream format is the most concise when filling in uncomplicated compound data. When the compound data contains complex deeply nested data, the stream format becomes difficult to understand due to the lack of explicit boundaries. At this time, the lite format is clearer and easier to read, and easier to master and use.
The json format and lua format require field names, and the data is more verbose. It is recommended to use them only in special occasions.
Streaming format
The streaming format is the default compact format, that is, when the format attribute is not specified in the header, the streaming format is used to parse the data. Before luban v4.0.0, only the streaming format is supported.
Data format
The rules for reading data in streaming format are as follows:
- bool false, true
- int, float and other valid integer values
- string uses "" to represent a string of length 0, and other non-values to represent the value itself
- enum non-null valid values
- bean uses streaming format to read each field in sequence
- Polymorphic bean type First read a string, which can be a specific subclass name or subcategory name, and then read each field of this type in streaming format according to the subclass name.
- Nullable bean type First read a string, if it is the bean type name or '{}', then read all fields of this type in streaming format; if it is null, it means empty and the reading ends; in other cases, it is treated as a non-null bean, starting from the string just read, and read the fields of this type.
Taking the vec3 type as an example,
1,2,3,null,{},1,2,3,vec3,1,2,3are all valid data - array,list,set If the stream ends or the next read is '}', the reading ends, otherwise read element_type in the stream format, and so on.
- map If the stream ends or the next read is '}', the reading ends, otherwise recursively read key_type and value_type, and so on.
Because the streaming format cannot distinguish between default cells and blank cells, it does not support default value semantics and ignores all blank cells. For the default value, you must fill in the valid default value to represent the data, and you cannot leave it blank to express it.
The example is as follows.
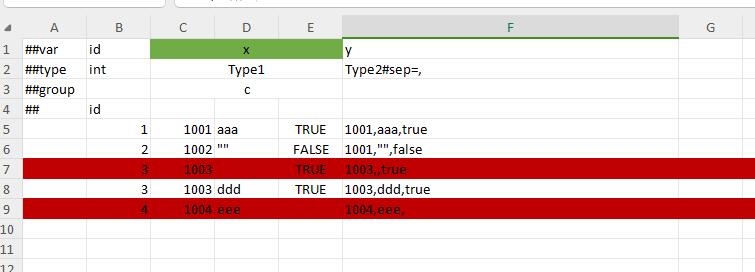
The two red lines in the figure try to use blank cells to express the default values of bool and string. Since these cells or the zero-length strings separated by sep will be ignored in the streaming format, the parsing error of insufficient data will occur.
sep segmentation mechanism
We call the data structure containing multiple atomic data elements a composite structure. For a composite structure, if each atomic data occupies a cell, there may be too many columns to read.
The sep segmentation mechanism can achieve the purpose of filling complex data in one cell.
The writing method is sep=<char1><char2><char3>.... sep can be one character or multiple characters. When sep is multiple characters, it means that any one of them is a separator,
rather than treating multiple characters as separators.
Since the # and & characters are used as delimiters for attrs and tags, if you need to use # or & as literal delimiters, you must escape them with a backslash (). For example: (list#sep=#),int.
sep can appear in the following positions:
- On the field name of Excel. Such as
x#sep=, - On the bean tag, such as
<bean name="Item" tag="sep=,"> - On the tag of the type field of field, such as
type="Vec#sep=,",type="(list#sep=|),int",type="list,(Vec#sep=,)",type="(list#sep=|),(Vec#sep=,)"
When it appears on the excel field name, the sep will be used to automatically split each cell in the column range of the field name to form a data stream, and then the streaming format (described in the following section) will be used to read these data in sequence.
When it appears on the bean tag, it means that all places where the bean is read will provide the entire bean data in string form, split with the separator and read in streaming format
When it appears on the type tag, the next data read will be regarded as the overall data corresponding to the type, and then the sep will be used to split the data, and then the data corresponding to the type will be read in streaming format.
When type is a container, the sep attribute can be applied to itself (such as list) or the element type. If the sep attribute is applied to itself, it means that the next string read in is regarded as the data of the entire container, and sep is used to split the string, and then the contents of the container are read in sequence in a streaming format. If the sep attribute is applied to the element type, each read content is regarded as the data of an element, and sep is used to split the data, and the data corresponding to the element type is read in a streaming format. Repeat this operation until there is no data or the container end character } is encountered.
Example: Use sep to read beans and nested beans.

Example: Use sep to read ordinary containers.
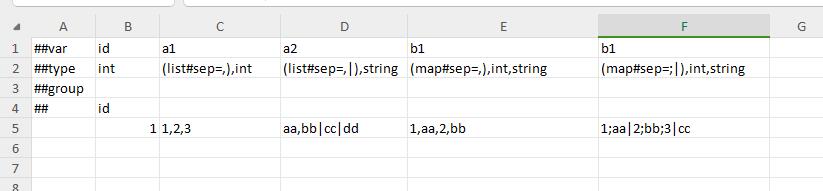
Example: Use sep to read structural containers.

lite format
Lite is a data format unique to Luban, suitable for expressing very complex nested data structures. The lite format is a format without field names, so it is more concise to fill in than the json and lua formats, and the parsing is more efficient. In practice, it is recommended to use the streaming format for simple composite data and the lite format for complex composite data. Use the json and lua formats only when necessary. For detailed documentation, see [lite format](./otherdatasource#lite format).
Use this format to parse data when the format attribute value is specified as lite in the header, such as position#format=lite.
Format example:
- vec3 data (1.0,2.0,3.0) is filled in as
{1.0, 2.0, 3.0}. class User{ int id; string name; vec3 pos;}is filled in as{1, xxxx, {1,2,3}}.
json format
Fill in data in json format. For detailed documentation, see [json format](./otherdatasource#json format).
Use this format to parse data when the format attribute value is specified as json in the header, such as position#format=json.
Format example:
vec3 data
(1.0,2.0,3.0)is filled in as{"x":1.0, "y":2.0, "z":3.0}.class User{ int id; string name; vec3 pos;}is filled in as{"id":1, "name":"xxxx", "pos":{"x":1, "y":2, "z":3}}.
lua format
Fill in data in lua format. For detailed documentation, see [lua format](./otherdatasource#lua format).
Use this format to parse data when the format attribute value is specified in the header, such as position#format=lua.
Format example:
- vec3 data
(1.0,2.0,3.0)is filled in as{x=1.0, y=2.0, z=3.0}in lua format. class User{ int id; string name; vec3 pos;}is filled in as{id=1, name="xxxx", pos={"x":1, "y":2, "z":3}}.